# Instalando um pacote individual
install.packages("tidyverse")
# Instalando múltiplos pacotes
install.packages(c("tidyverse", "readxl", "janitor"))2 Manipulação de Dados com Tidyverse
2.1 O que é o Tidyverse?
O tidyverse é uma coleção de pacotes R projetados para ciência de dados. Todos os pacotes compartilham uma filosofia de design, gramática e estruturas de dados subjacentes, tornando o trabalho com dados mais intuitivo e eficiente.
2.1.1 Pacotes Principais do Tidyverse
- dplyr: Manipulação de dados (filtrar, selecionar, agrupar, sumarizar)
- ggplot2: Criação de gráficos elegantes
- tidyr: Organização e limpeza de dados
- readr: Leitura rápida de dados tabulares (CSV, TSV)
- purrr: Programação funcional
- tibble: Versão moderna de data frames
- stringr: Manipulação de strings
- forcats: Manipulação de fatores
2.1.2 Por que usar o Tidyverse?
- Código mais legível: Sintaxe intuitiva e consistente
- Pipe operator: Encadeamento de operações de forma natural |> ou %>%
- Eficiência: Otimizado para grandes volumes de dados
- Comunidade: Ampla documentação e suporte
- Integração: Pacotes desenvolvidos com funcionalidade integrada
2.2 Instalação e Carregamento de Pacotes
2.2.1 Instalando Pacotes
Para instalar um pacote no R, usamos a função install.packages():
Importante: Você só precisa instalar um pacote uma vez. Após a instalação, o pacote fica disponível permanentemente.
2.2.2 Carregando Pacotes
Após instalados, os pacotes precisam ser carregados em cada sessão usando library():
2.3 Importando Dados
2.3.1 Leitura de Arquivos Excel
A função read_excel() do pacote readxl permite importar dados de arquivos Excel:
# Importando dados de internações hospitalares
dados <- read_excel("data/dados_internacoes_maringa_2024.xlsx")
Sobre o diretório de trabalho
Importante: Sempre verifique se você está no diretório correto. Coloque os scripts e dados para análise em um mesmo diretório.
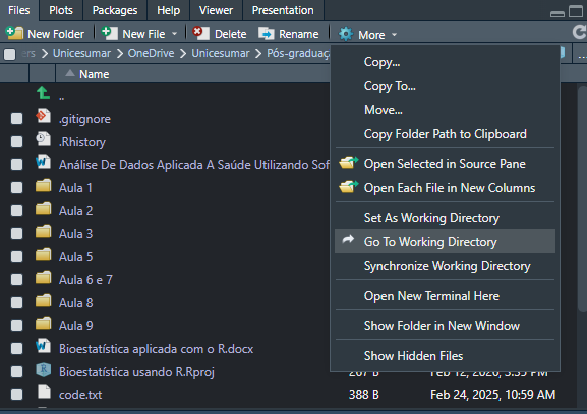
O R só reconhece arquivos que está pasta do diretório de trabalho.
Para selecionar essa pasta, clique nos … na imagem, selecione a pasta com os scripts e dados e clique em Set as working directory.
Organização das pastas no diretório de trabalho
Organize os dados e os scripts em pastas, para todos os arquivos ficarem organizados.
Sugestão de organização:
Pasta data, com os dados brutos e filtrados/analisados
Pasta scripts, com os scripts utilizados na análise
Pasta figuras, com as figuras geradas
Pasta tabelas, com as tabelas geradas
Pasta manuscrito, se utilizar o R para escrita científica
Sobre os dados utilizados nesse livro.
Os dados utilizados neste livro são de internações hospitalares de Maringá-PR referentes ao ano de 2024, disponibilizados pelo Sistema de Informações Hospitalares (SIH) do SUS. Os dados são anonimizados e de domínio público.
O arquivo dados_internacoes_maringa_2024.xlsx deve estar na pasta data/ do seu projeto.
2.3.2 Explorando os Dados Importados
Após importar, é importante explorar a estrutura dos dados:
Essas funções fornecem informações sobre:
- Número de linhas e colunas
- Tipos de dados de cada variável
- Primeiros valores de cada coluna
- Valores ausentes (NAs)
2.4 Principais Funções do Tidyverse
O tidyverse oferece um conjunto de funções poderosas para manipulação de dados:
| Função | Descrição |
|---|---|
select() |
Seleciona colunas específicas |
filter() |
Filtra linhas baseado em condições |
mutate() |
Cria ou modifica colunas |
rename() |
Renomeia colunas |
group_by() |
Agrupa dados por variáveis |
summarise() |
Calcula estatísticas resumidas |
Vamos explorar cada uma dessas funções em detalhes.
2.4.1 select(): Selecionando Colunas
A função select() permite escolher quais colunas manter no seu data frame:
2.4.1.1 Excluindo Colunas
Você pode também remover colunas específicas usando o sinal de menos -:
# Removendo a coluna CEP
dados2 <- select(dados, -CEP)2.4.1.2 Seleção Avançada
# Selecionar colunas que começam com determinado texto
select(dados, starts_with("VAL"))
# Selecionar colunas que terminam com determinado texto
select(dados, ends_with("_TOT"))
# Selecionar colunas que contêm determinado texto
select(dados, contains("IDADE"))
# Selecionar colunas numéricas
select(dados, where(is.numeric))2.4.2 filter(): Filtrando Linhas
A função filter() permite selecionar linhas que atendem a determinadas condições:
2.4.2.1 Filtro Simples
2.4.2.2 Múltiplas Condições
Use o operador & (E) para combinar condições:
2.4.2.3 Outros Operadores Lógicos
# Operador OU (|): pacientes com idade menor que 18 OU maior que 60
filter(dados, IDADE < 18 | IDADE > 60)
# Operador %in%: selecionar múltiplos valores
filter(dados, RACA_COR %in% c("Branca", "Parda"))
# Valores ausentes
filter(dados, is.na(IDADE)) # Linhas com idade ausente
filter(dados, !is.na(IDADE)) # Linhas SEM idade ausente2.4.3 mutate(): Criando e Modificando Colunas
A função mutate() é usada para criar novas colunas ou modificar existentes:
2.4.3.1 Criando Nova Coluna
# Criando nova coluna com valor total multiplicado por 1000
dados_valor_1000 <- mutate(dados, VAL_TOT_1000 = VAL_TOT * 1000)2.4.3.2 Modificando Tipo de Dados
A função across() permite aplicar uma transformação a múltiplas colunas:
2.4.3.3 Recodificando Variáveis com case_when()
A função case_when() é útil para criar categorias baseadas em múltiplas condições:
Outros exemplos de case_when():
# Classificando faixas etárias
dados <- mutate(
dados,
faixa_etaria = case_when(
IDADE < 18 ~ "Criança/Adolescente",
IDADE >= 18 & IDADE < 60 ~ "Adulto",
IDADE >= 60 ~ "Idoso"
)
)
# Classificando permanência hospitalar
dados <- mutate(
dados,
tempo_internacao = case_when(
DIAS_PERM <= 3 ~ "Curta",
DIAS_PERM > 3 & DIAS_PERM <= 7 ~ "Média",
DIAS_PERM > 7 ~ "Longa"
)
)2.4.4 rename(): Renomeando Colunas
A função rename() permite alterar nomes de colunas:
# Renomeando a coluna ESPEC para ESPECIALIDADE
dados <- rename(dados, ESPECIALIDADE = ESPEC)
# Sintaxe: novo_nome = nome_antigoRenomeando múltiplas colunas:
dados <- rename(
dados,
especialidade = ESPEC,
diagnostico = DIAG_PRINC,
idade_anos = IDADE
)2.4.5 group_by() e summarise(): Sumarizando Dados
Estas funções trabalham em conjunto para calcular estatísticas agrupadas.
2.4.5.1 Agrupamento e Sumarização Básica
2.4.5.2 Múltiplas Estatísticas
# Calculando várias estatísticas ao mesmo tempo
estatisticas <- dados |>
group_by(SEXO) |>
summarise(
n = n(), # Contagem
idade_media = mean(IDADE, na.rm = TRUE),
idade_dp = sd(IDADE, na.rm = TRUE),
idade_mediana = median(IDADE, na.rm = TRUE),
idade_min = min(IDADE, na.rm = TRUE),
idade_max = max(IDADE, na.rm = TRUE),
.groups = "drop"
)2.5 O Operador Pipe |>
O pipe operator |> é uma das ferramentas mais úteis do tidyverse. Ele permite encadear múltiplas operações de forma legível.
2.5.1 Como Ler o Pipe
O símbolo |> pode ser lido como “E ENTÃO” ou “PASSE PARA”.
Leitura: “Pegue os dados E ENTÃO filtre para sexo masculino E ENTÃO agrupe por raça/cor E ENTÃO calcule a média de idade”
2.5.2 Atalho de Teclado
-
Windows/Linux:
Ctrl + Shift + M -
Mac:
Cmd + Shift + M
Pipe Nativo vs. Pipe do magrittr
O R possui dois operadores pipe:
-
|>- Pipe nativo do R (versão 4.1+) - usado neste livro -
%>%- Pipe do pacote magrittr
Ambos funcionam de forma similar. Usamos |> por ser a implementação oficial e não requerer pacotes adicionais.
2.6 Encadeamento de Operações
O verdadeiro poder do tidyverse aparece quando combinamos múltiplas operações:
2.6.1 Exemplo Completo de Pipeline
# Pipeline complexo de limpeza e análise de dados
dados_limpos <- dados |>
# 1. Selecionar colunas relevantes
select(SEXO, RACA_COR, IDADE, MORTE, COD_IDADE) |>
# 2. Filtrar apenas idades em anos
filter(COD_IDADE == "Anos") |>
# 3. Remover coluna COD_IDADE (não mais necessária)
select(-COD_IDADE) |>
# 4. Converter IDADE para numérico
mutate(across(IDADE, as.numeric)) |>
# 5. Converter variáveis categóricas para fator
mutate(across(c(SEXO, RACA_COR, MORTE), as.factor)) |>
# 6. Recodificar raça/cor
mutate(RACA_COR = case_when(
RACA_COR == '01' ~ "Branca",
RACA_COR == "02" ~ "Preta",
RACA_COR == "03" ~ "Parda",
RACA_COR == "04" ~ "Amarela",
RACA_COR == "05" ~ "Indígena"
)) |>
# 7. Renomear colunas para minúsculas
rename(
sexo = SEXO,
raca_cor = RACA_COR,
idade = IDADE,
morte = MORTE
) |>
# 8. Agrupar por raça/cor e sexo
group_by(raca_cor, sexo) |>
# 9. Calcular idade média por grupo
summarise(mean_idade = mean(idade), .groups = "drop")
dados_limpos2.6.2 Vantagens do Encadeamento
- Legibilidade: Código lido de cima para baixo, como uma receita
- Manutenção: Fácil adicionar, remover ou modificar etapas
- Eficiência: Evita criar múltiplos objetos intermediários
- Debug: Fácil testar executando até determinado ponto
2.6.3 Dica para Debug
Você pode executar o pipeline até qualquer ponto selecionando o código desejado:
2.7 Outras Funções Úteis do dplyr
2.7.1 arrange(): Ordenando Dados
2.7.2 count(): Contagem Rápida
2.7.3 distinct(): Valores Únicos
2.7.4 slice(): Seleção por Posição
2.8 Pacote janitor: Limpeza de Nomes
O pacote janitor oferece funções úteis para limpeza de dados, especialmente nomes de colunas:
library(janitor)
# Limpar nomes de colunas (remove acentos, espaços, caracteres especiais)
dados <- clean_names(dados)
# Antes: "Nome da Variável"
# Depois: "nome_da_variavel"2.9 Resumo do Capítulo
Neste capítulo, você aprendeu:
- O que é o tidyverse e seus principais pacotes
- Como instalar e carregar pacotes no R
-
Importar dados de arquivos Excel com
read_excel() -
Explorar dados com
summary(),glimpse()estr() -
Principais funções do dplyr:
-
select()- Selecionar colunas -
filter()- Filtrar linhas -
mutate()- Criar/modificar colunas -
rename()- Renomear colunas -
group_by()esummarise()- Agrupar e sumarizar
-
-
Usar o pipe operator
|>para encadear operações - Criar pipelines complexos de limpeza e análise de dados
-
Funções adicionais como
arrange(),count(),distinct(),slice()
No próximo capítulo, você aprenderá a realizar análises exploratórias de dados, incluindo estatística descritiva, testes estatísticos e visualização com ggplot2.
2.10 Exercícios Práticos
Carregue o arquivo
dados_internacoes_maringa_2024.xlsxe explore sua estrutura-
Crie um pipeline que:
- Selecione as colunas SEXO, IDADE, DIAS_PERM, VAL_TOT, MORTE
- Filtre apenas pacientes adultos (IDADE >= 18)
- Crie uma coluna categorizando o tempo de permanência (curta: ≤3 dias, média: 4-7 dias, longa: >7 dias)
- Calcule a idade média e o valor total médio por sexo e categoria de permanência
Identifique as 10 especialidades médicas com maior número de internações